Joint Text Embedding for Personalised Content-based Recommendation
TLDR
Learning user and text embedding for personalised recommendation of new textual items. Embedding are learnt by treating the problem as a ranking problem and increasing the proximity score for each positive user-item pair and vice-versa for negative user-item pair. Item are embedded using their associated text. Text embedding are also learnt during the learning to rank process. To tackle the problem of unseen text and reduce overfitting,an unsupervised pretrained text embedding component is added to text embedding module.
Introduction
It is very common to encounter the problem of personalised recommendation for relatively new item without prior user interaction (Cold start problem). For many use cases, the only meta data associated with the item is text. For example; Quora question recommendation where every day new set questions are populated. Google News recommendation based on news article text to the user.
Learning a joint text embedding (user and item) for such items is useful to let use compare user and item similarity, while also facilitating to solve the cold start problem. Users and text item can be simulataneously embedded into a latent space where preferences can be depicted by a dot product.
Problem Statement
Personalised recommendation for completely new items with text information available.
Methodology
The task is to learn joint embedding for user and item. The paper treats it as a ranking problem where item which is more likely to be clicked/liked needs to be ranked higher. During this process of learning to rank,we learn both user as well as the text embedding.
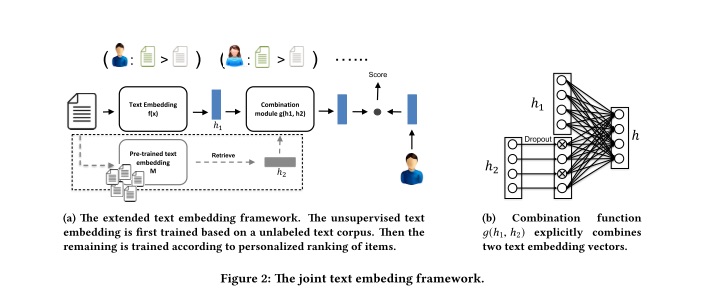
The proximity score between the user and item pair (i,j) is computed as a dot product \(s_{ij} = u_i \f{x_j}\). The objective is to rank user’s interest articles higher than those he/she is not interested in.
The score difference between positive and negative items is maximized, leading to the pairwise ranking loss function as
\(\mathcal{L}=\mathbb{E}_{(i, p, n) \sim \mathcal{D}}\left[-\log \sigma\left(s_{i,p}-s_{i,n}\right)\right]\)
Each triplet is drawn from some predefined data distribution and \(\sigma\) is sigmoid function.
Now, \(\f(x_j)\) encodes text to an embedding. There are two parts to this function.
- Unsupervised pretrained text embedding (h2)
- This could be any embedding techinque(Word2vec, LSTM , CNN) pretrained on the item text corpus or any general corpus. This is reponsible to encode new unknown text, solving the cold start problem.
- Supervised text embedding (h1):
- This textual embedding is learnt during the training process. h1 and h2 are combined using a single layer NN.
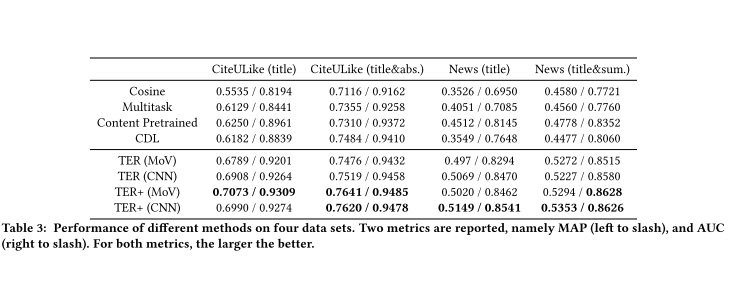
Evaluation
For evaluation MAP (Mean Average Precision) and average AUC used. Below are the results on different datasets.